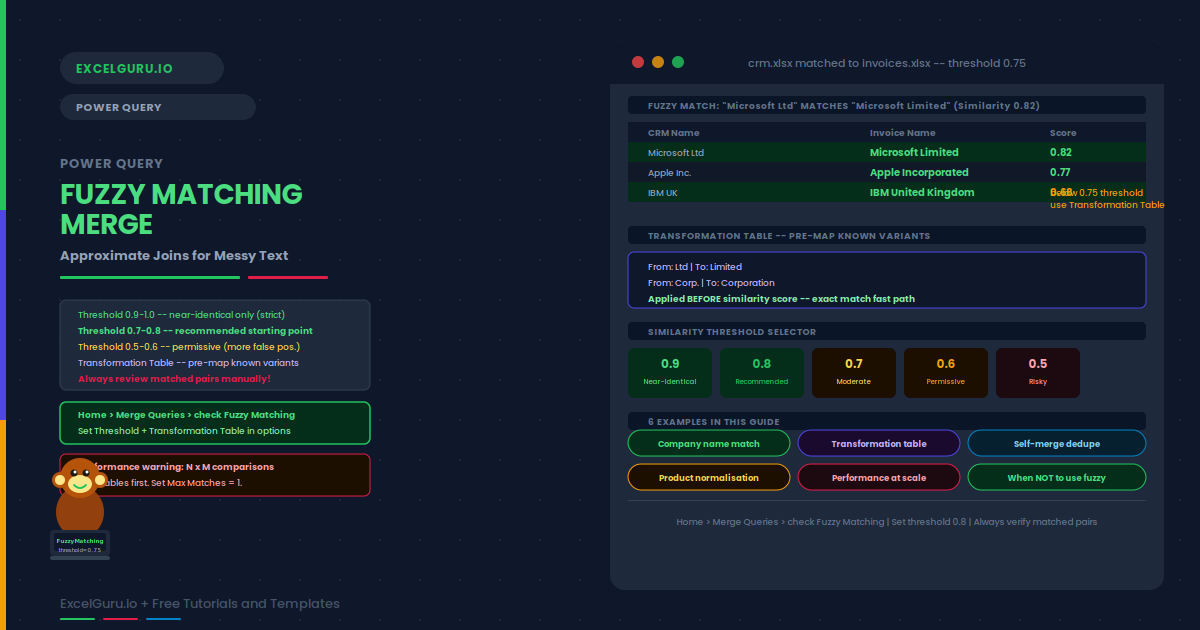
Customer name "Microsoft Corp." in one table. "Microsoft Corporation" in another. A standard merge finds no match. Fuzzy Matching in Power Query solves this. It finds rows that are similar but not identical, using a similarity threshold you control. Instead of requiring an exact text match, it accepts a percentage similarity — so "Microsoft Corp." and "Microsoft Corporation" merge successfully when the threshold is set to 0.7 or lower.
This guide covers how fuzzy matching works, the similarity threshold and transformation table options, when to use it versus cleaning data first, its limitations on large datasets, and six practical examples. These include company name matching, address deduplication, product name normalisation, and combining two survey datasets with inconsistent respondent names.
How Does Fuzzy Matching Work?
Power Query’s fuzzy matching uses the Jaccard similarity coefficient on character n-grams to compare text values. In simple terms, it breaks each string into overlapping character groups and counts how many groups are shared between two strings. Two identical strings score 1.0. Completely different strings score 0.0. You set a similarity threshold between 0 and 1, and any pair scoring above that threshold is considered a match.
The Similarity Threshold is the most important setting. A threshold of 0.8 is strict — it requires strings to be at least 80% similar. A threshold of 0.6 is more permissive. Start with 0.8 and lower it if too few matches are found. Raise it if too many incorrect matches appear. There is no perfect universal threshold — it depends on how inconsistent your specific data is.
| Threshold | Match sensitivity | Risk | Typical use |
|---|---|---|---|
| 0.9 – 1.0 | Very strict (near-identical) | Misses partial matches | Typo correction only |
| 0.7 – 0.8 | Moderate (recommended start) | Some false positives | Company names, product titles |
| 0.5 – 0.6 | Permissive | Many false positives | Short strings, abbreviations |
| Below 0.5 | Very loose | Unreliable; verify manually | Rarely appropriate |
How to Perform a Fuzzy Merge in Power Query
Examples 1–4: Fuzzy Matching in Practice
A CRM has company names in one format ("Microsoft Ltd"). An invoicing system uses a different format ("Microsoft Limited"). A standard join finds zero matches. Fuzzy matching at threshold 0.75 correctly matches these name variants and brings the invoice data alongside the CRM records.
A Transformation Table is a two-column lookup that maps known "From" values to their correct "To" values. Power Query applies these substitutions before calculating similarity scores. This means known abbreviations and shorthand forms always match correctly, regardless of similarity threshold. It supplements fuzzy matching rather than replacing it.
To find near-duplicate values within one table — such as a customer list with "Alice Chen" and "Alice Chan" — merge the table against itself (Merge Queries as New, using the same query as both the left and right table). Set a high threshold (0.85+) and filter out exact self-matches (similarity = 1.0). The remaining matches are likely near-duplicates for manual review.
A product catalogue has "Widget Pro 2.0 (Blue)" in the master list. A sales export has "Widget Pro 2 Blue" and "Widget Pro 2.0 Blue". An exact join fails. Fuzzy matching at threshold 0.78 catches both variants. Combining fuzzy matching with a transformation table that normalises common patterns (removes parentheses, standardises version numbers) improves accuracy further.
Examples 5–6: Limitations and Alternatives
Fuzzy matching is computationally expensive because every pair of values from both tables must be compared. On a 10,000 x 10,000 row merge, that is 100 million comparisons. Performance degrades sharply on large datasets. The practical workarounds are: pre-filter both tables to reduce row counts, use a transformation table to convert known variants to exact matches before the fuzzy step, or use an exact merge on a normalised key column instead of relying entirely on fuzzy logic.
Fuzzy matching is a last resort, not a first step. When inconsistencies are caused by predictable patterns (extra spaces, mixed case, punctuation), cleaning the key column first and then using an exact merge is faster, more reliable, and easier to maintain. Fuzzy matching should be reserved for truly unpredictable variations where automated cleaning cannot predict the correct form.
Common Issues and How to Fix Them
Fuzzy merge returns no matches or too few matches
Lower the similarity threshold. Start at 0.8 and drop by 0.05 at a time until matches appear. Also check "Ignore Case" and "Ignore Space" — these options can significantly increase the match rate for strings that differ only in capitalisation or spacing. Additionally, add a transformation table to convert known abbreviations to their full form before the similarity calculation runs.
Fuzzy merge returns too many incorrect matches
Raise the similarity threshold. A threshold above 0.85 requires strings to be very similar before matching. Additionally, review the matched pairs in the output and add explicit non-matches to the transformation table (map them to a placeholder like "NO-MATCH" which will fail to match anything). Cleaning the source data before the fuzzy step — removing punctuation, standardising abbreviations — also reduces false positives.
Frequently Asked Questions
-
What is fuzzy matching in Power Query?+Fuzzy matching is a merge option in Power Query that joins rows based on approximate text similarity rather than exact equality. It compares text values using a similarity score from 0 (completely different) to 1 (identical). You set a threshold, and any pair scoring above it is considered a match. This allows "Microsoft Ltd" to match "Microsoft Limited" even though the strings are not identical. Access it via Home → Merge Queries, then check "Use fuzzy matching to perform the merge".
-
What similarity threshold should I use?+Start with 0.8 and adjust based on results. A threshold of 0.8 requires strings to be at least 80% similar — good for company names and product titles with minor variations. Lower to 0.7 or 0.6 if you have heavily abbreviated or shortened strings. Raise to 0.9 if you are only correcting minor typos. Always review the matched output manually and adjust the threshold based on the quality of matches you see.
-
What is a Transformation Table in fuzzy matching?+A Transformation Table is a two-column Power Query table with a "From" column and a "To" column. It maps known incorrect or abbreviated values to their correct forms before the fuzzy similarity calculation runs. For example, mapping "Ltd" to "Limited" or "Corp." to "Corporation" ensures these known variants always match correctly, regardless of the similarity threshold. Add it in the fuzzy merge options dialog via the "Transformation Table" dropdown.
-
Is fuzzy matching slow on large tables?+Yes. Fuzzy matching compares every value in the left table against every value in the right table, so performance scales quadratically with row count. A merge of 10,000 rows against 10,000 rows requires 100 million comparisons. Reduce performance impact by filtering both tables before merging, using a Transformation Table for known variants (exact matches are faster), setting Maximum Matches to 1, and pre-cleaning the key columns so fewer fuzzy comparisons are needed.