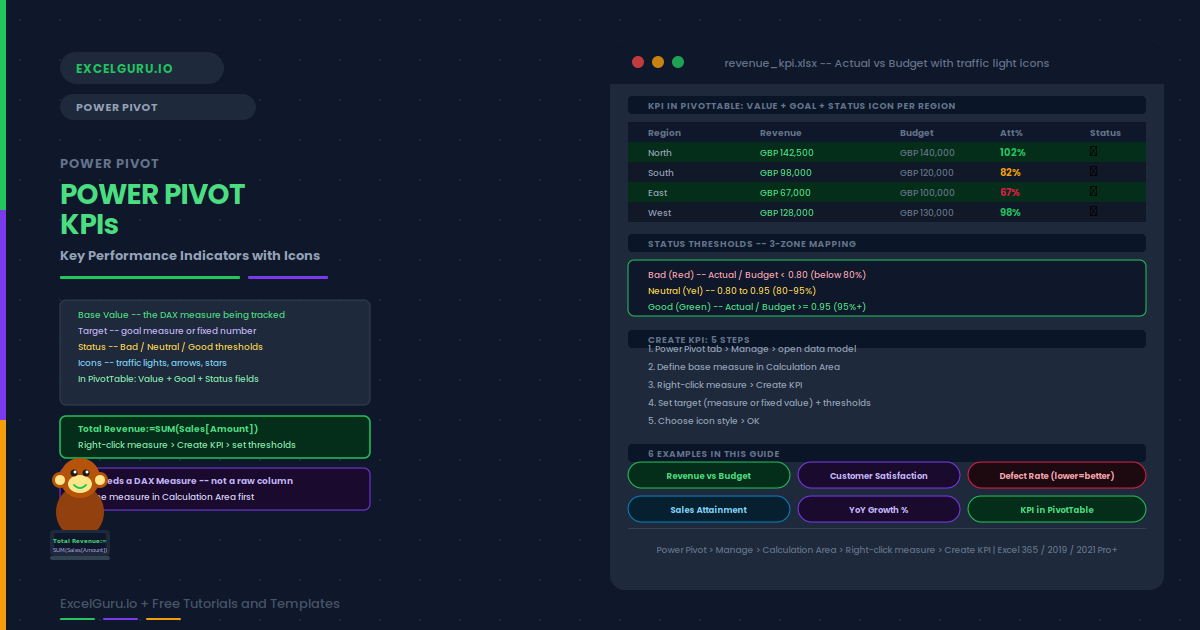
Power Pivot KPIs: Create Key Performance Indicators with Icons in Excel
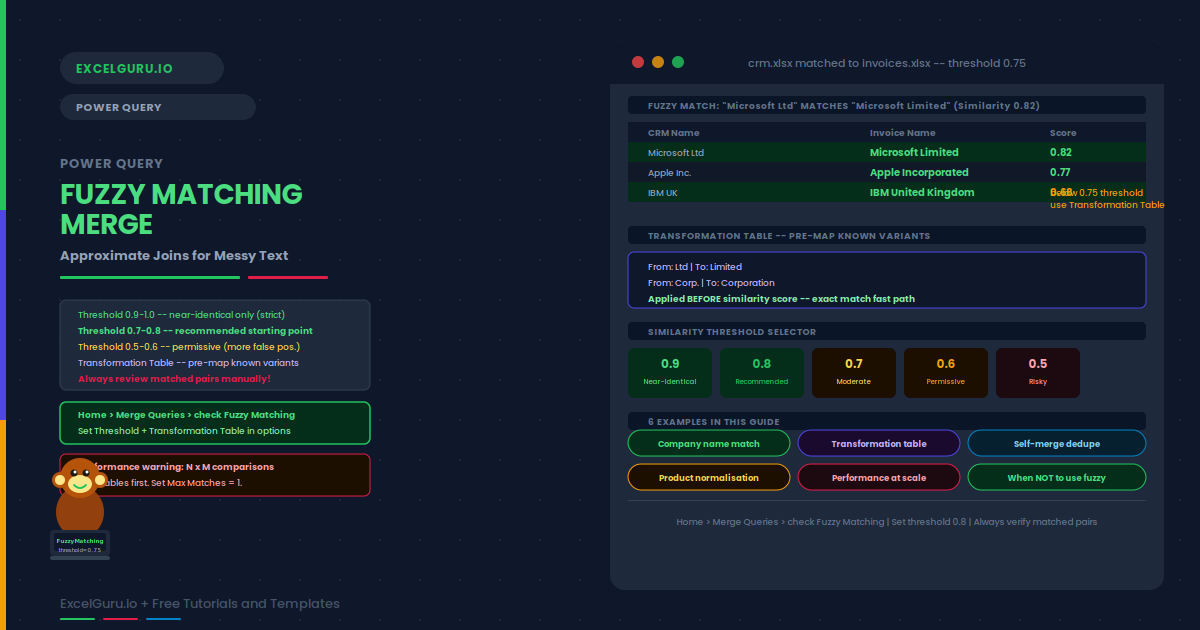
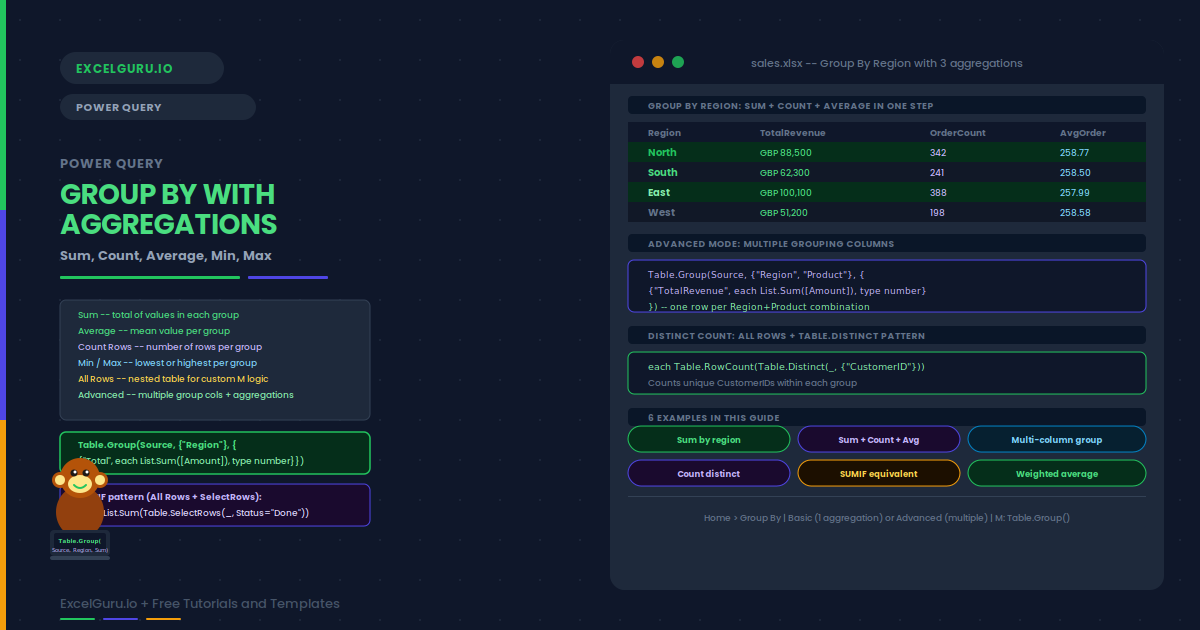
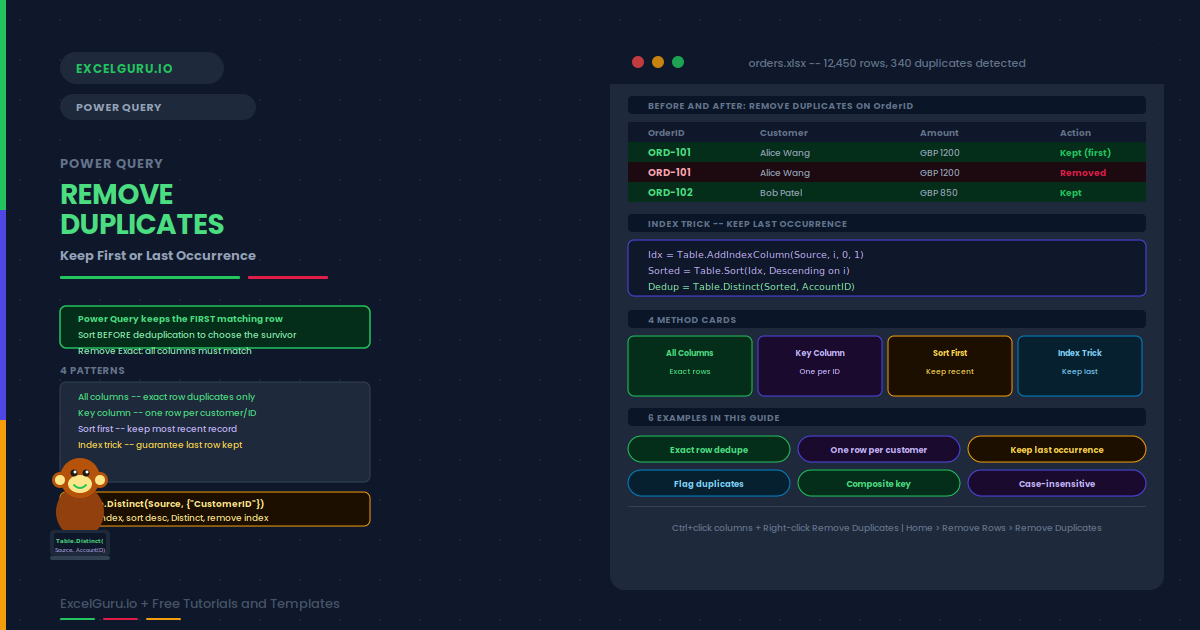
A KPI in Power Pivot is more than a number — it is a comparison with a visual verdict. You define a base measure (Actual Revenue), a target (Budget Revenue), and two threshold values that divide performance into bad (red), neutral (yellow), and good (green). Power Pivot calculates the ratio automatically and displays a traffic light, arrow, or star icon in the PivotTable alongside the value and the goal. No conditional formatting setup is needed — the logic lives in the data model and updates on every refresh. This guide covers the full five-step creation workflow, the three KPI components, how to handle reversed thresholds for metrics where lower is better (defect rate, churn), Year-over-Year growth KPIs with a zero baseline, Sales Attainment with star rating icons, and the correct way to display Value, Goal, and Status fields together in a polished PivotTable layout.