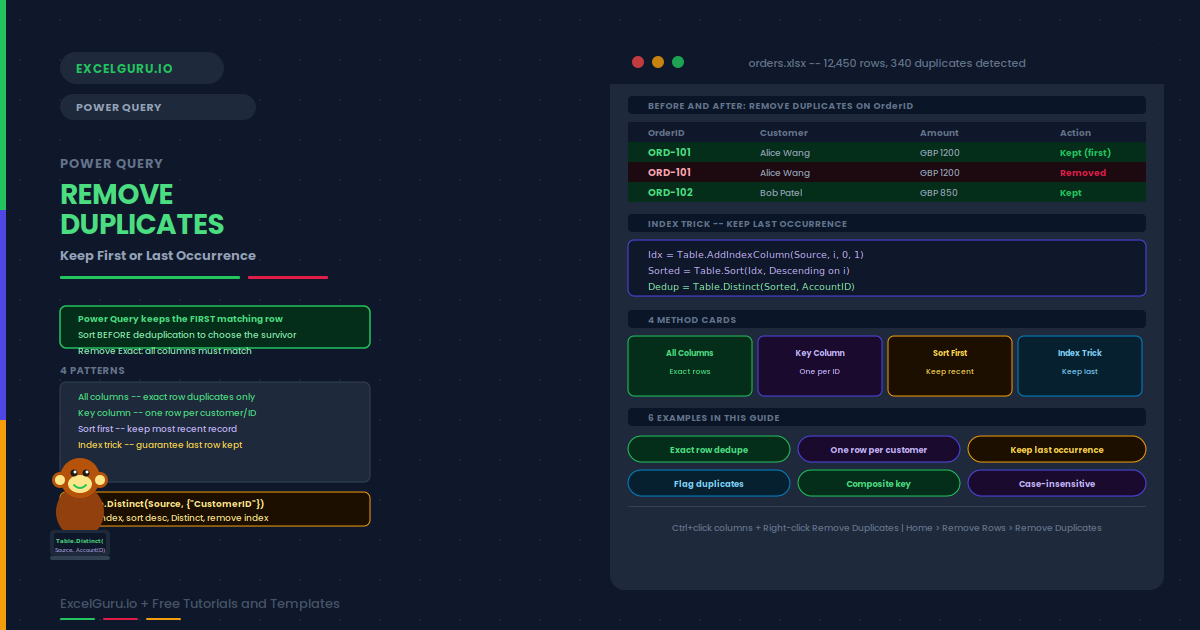
Your data has 50,000 rows and you suspect duplicates are inflating your totals. Power Query’s Remove Duplicates cleans them in a single step — but that step hides an important choice. By default, Power Query keeps the first occurrence of each duplicate group. With one extra sort step beforehand, you control exactly which row survives: the most recent, the highest value, or the last entry received.
This guide covers the full Remove Duplicates workflow, including one-column and multi-column deduplication, keeping last occurrences, flagging duplicates instead of deleting them, and handling case-sensitive mismatches. Six worked examples cover customer records, sales transactions, product catalogues, and composite key scenarios.
How Does Power Query Identify Duplicates?
Power Query compares rows based on the columns you select when applying Remove Duplicates. If you select all columns, only exact duplicate rows are removed. If you select a single column such as CustomerID, the first row for each CustomerID is kept and all subsequent rows for that ID are removed, regardless of how the other columns differ.
Row order determines which duplicate survives. Power Query scans top-to-bottom and keeps the first matching row. Consequently, controlling the sort order before deduplication is the key technique for all advanced scenarios. Additionally, the M function Table.Distinct is the underlying code for Remove Duplicates and accepts a list of key columns as its second argument.
| Method | What is compared | Typical use case |
|---|---|---|
| All columns | Every column must match exactly | Remove exact duplicate rows from merged imports |
| Key column(s) only | Selected columns must match | Keep one row per customer, order, or product SKU |
| Sort then Remove | Same as above | Keep most recent date or highest value row |
| Index reverse trick | Same, but row order reversed first | Guarantee the last occurrence is kept |
How to Remove Duplicates in Power Query
Examples 1–4: Core Deduplication Patterns
A CRM export appended with a second report produces 340 exact duplicate rows. Every column — OrderID, Customer, Date, and Amount — is identical between pairs. Home → Remove Rows → Remove Duplicates eliminates all duplicates in one step because it compares all columns simultaneously.
Result: 12,110 rows from 12,450. The 340 exact duplicates are removed. The first occurrence of each duplicate pair is kept.
A transaction table has multiple rows per customer. You need one row per customer for a mailing list. Selecting only the CustomerID column before Remove Duplicates keeps one row per ID — the first in the current sort order — and removes all later ones, regardless of what other columns contain.
Keeping the genuinely last row requires reversing the order before deduplication. The Index column trick achieves this reliably. After adding an index and sorting it descending, the last original row becomes the first — so Remove Duplicates preserves it.
Instead of deleting duplicates, you can add a True/False flag column for manual review. This is useful when duplicates might have conflicting values that need investigation before removal. The technique uses a duplicated query to count occurrences and merges the count back as a flag.
Examples 5–6: Composite Keys and Case-Insensitive Deduplication
No single column is unique, but the combination of Region and Month should be. Ctrl-click both column headers before Remove Duplicates to use both as the composite key. Power Query then keeps one row per Region-Month pair and removes the rest.
Power Query is case-sensitive by default. "Excel" and "excel" survive as separate rows. To deduplicate case-insensitively, add a temporary lowercase helper column, deduplicate on that, then remove the helper. The original casing is preserved in the source column throughout.
Common Issues and How to Fix Them
Remove Duplicates kept the wrong row
The wrong row survived because the table was not sorted in the intended order before deduplication. Power Query always keeps the first matching row. Add a Sort step before Remove Duplicates to put the desired row first. For example, sort by Date descending to keep the most recent row, or sort by Amount descending to keep the highest-value row per key.
Duplicates still appear after deduplication
The remaining "duplicates" likely have subtle differences: trailing spaces, different capitalisation, or time components in a date-time field. Apply Trim and Clean to text columns, Text.Lower for case normalisation, and Date.Date() to strip time from date-time values before deduplicating. These transformations should be added as steps before the Remove Duplicates step so they always run on every refresh.
Frequently Asked Questions
-
How do I remove duplicates in Power Query?+To remove entire-row duplicates, go to Home → Remove Rows → Remove Duplicates. To remove duplicates based on specific columns, Ctrl-click those column headers, right-click, and choose Remove Duplicates. Power Query keeps the first occurrence of each duplicate group based on the current row order. Sort the table first to control which row is preserved.
-
How do I keep the last duplicate instead of the first?+Add an Index column (Add Column → Index Column → From 0). Sort the index column descending so the last original row is now first. Apply Remove Duplicates on the key column. Remove the index column. The row that was originally last now survives. In M code: Table.Distinct(Table.Sort(Table.AddIndexColumn(Source, "i", 0, 1), {{"i", Order.Descending}}), {"KeyColumn"}).
-
Is Power Query deduplication case-sensitive?+Yes. By default, "Excel" and "excel" are treated as different values. To deduplicate case-insensitively, add a helper column using Text.Lower([Column]), apply Remove Duplicates on the helper column, then remove it. The original column keeps its original casing while the deduplication logic treats all variations as equivalent.
-
Can I flag duplicates instead of removing them?+Yes. Duplicate the query, group by the key column and count rows, then merge the count back to the original as a new column. Add a conditional column where Count greater than 1 equals TRUE. Each row then has a True/False IsDuplicate flag. Filter to TRUE in Excel to review all duplicate rows before deciding whether to delete them.